# 深入分析虚拟 dom 的渲染原理和特性

# 导读
React的虚拟DOM和Diff算法是React的非常重要的核心特性,这部分源码也非常复杂,理解这部分知识的原理对更深入的掌握React是非常必要的。
本来想将虚拟DOM和Diff算法放到一篇文章,写完虚拟DOM发现文章已经很长了,所以本篇只分析虚拟DOM。
本篇文章从源码出发,分析虚拟DOM的核心渲染原理(首次渲染),以及React对它做的性能优化点。
说实话React源码真的很难读 😅,如果本篇文章帮助到了你,那么请给个赞 👍 支持一下吧。
# 开发中的常见问题
- 为何必须引用
React - 自定义的
React组件为何必须大写 React如何防止XSSReact的Diff算法和其他的Diff算法有何区别key在React中的作用- 如何写出高性能的
React组件
如果你对上面几个问题还存在疑问,说明你对React的虚拟DOM以及Diff算法实现原理还有所欠缺,那么请好好阅读本篇文章吧。
首先我们来看看到底什么是虚拟DOM:
# 虚拟 DOM
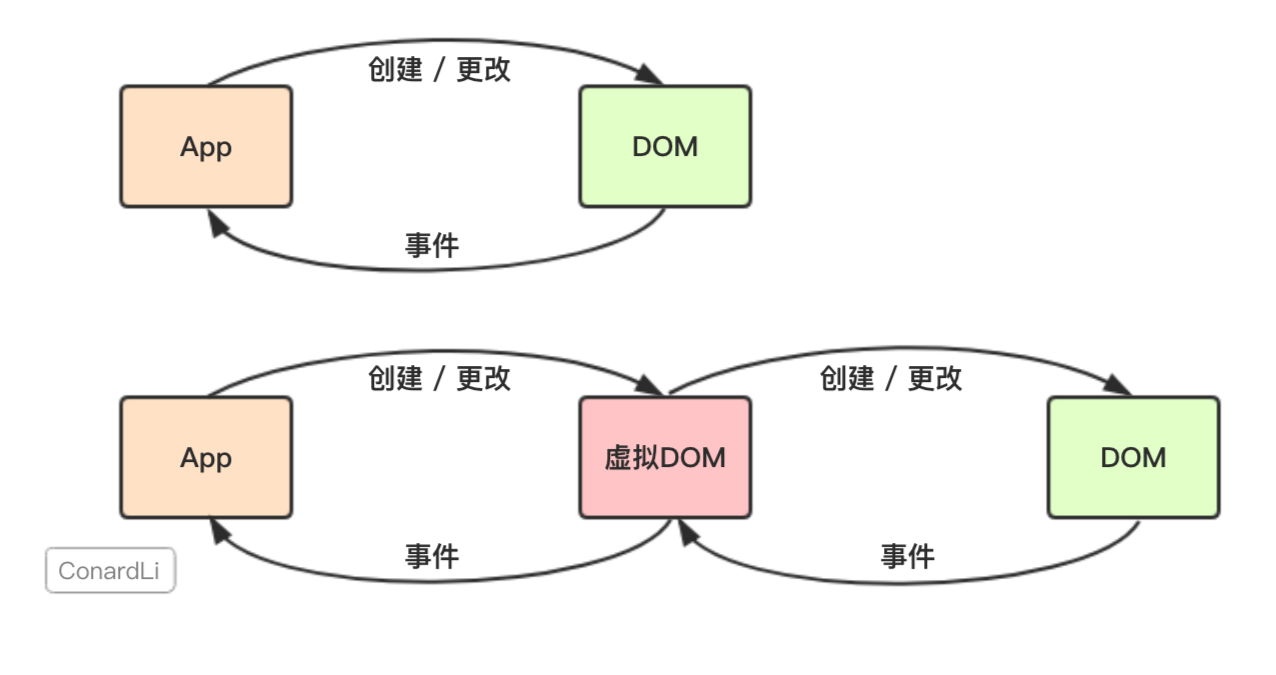
在原生的JavaScript程序中,我们直接对DOM进行创建和更改,而DOM元素通过我们监听的事件和我们的应用程序进行通讯。
而React会先将你的代码转换成一个JavaScript对象,然后这个JavaScript对象再转换成真实DOM。这个JavaScript对象就是所谓的虚拟DOM。
比如下面一段html代码:
<div class="title">
<span>Hello ConardLi</span>
<ul>
<li>苹果</li>
<li>橘子</li>
</ul>
</div>
在React可能存储为这样的JS代码:
const VitrualDom = {
type: "div",
props: { class: "title" },
children: [
{
type: "span",
children: "Hello ConardLi",
},
{
type: "ul",
children: [
{ type: "ul", children: "苹果" },
{ type: "ul", children: "橘子" },
],
},
],
};
当我们需要创建或更新元素时,React首先会让这个VitrualDom对象进行创建和更改,然后再将VitrualDom对象渲染成真实DOM;
当我们需要对DOM进行事件监听时,首先对VitrualDom进行事件监听,VitrualDom会代理原生的DOM事件从而做出响应。
# 为何使用虚拟 DOM
React为何采用VitrualDom这种方案呢?
# 提高开发效率
使用JavaScript,我们在编写应用程序时的关注点在于如何更新DOM。
使用React,你只需要告诉React你想让视图处于什么状态,React则通过VitrualDom确保DOM与该状态相匹配。你不必自己去完成属性操作、事件处理、DOM更新,React会替你完成这一切。
这让我们更关注我们的业务逻辑而非DOM操作,这一点即可大大提升我们的开发效率。
# 关于提升性能
很多文章说VitrualDom可以提升性能,这一说法实际上是很片面的。
直接操作DOM是非常耗费性能的,这一点毋庸置疑。但是React使用VitrualDom也是无法避免操作DOM的。
如果是首次渲染,VitrualDom不具有任何优势,甚至它要进行更多的计算,消耗更多的内存。
VitrualDom的优势在于React的Diff算法和批处理策略,React在页面更新之前,提前计算好了如何进行更新和渲染DOM。实际上,这个计算过程我们在直接操作DOM时,也是可以自己判断和实现的,但是一定会耗费非常多的精力和时间,而且往往我们自己做的是不如React好的。所以,在这个过程中React帮助我们"提升了性能"。
所以,我更倾向于说,VitrualDom帮助我们提高了开发效率,在重复渲染时它帮助我们计算如何更高效的更新,而不是它比DOM操作更快。
如果您对本部分的分析有什么不同见解,欢迎在评论区拍砖。
# 跨浏览器兼容
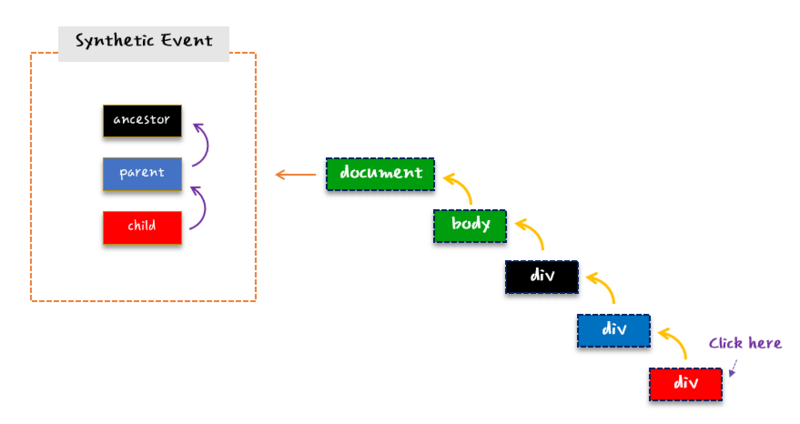
React基于VitrualDom自己实现了一套自己的事件机制,自己模拟了事件冒泡和捕获的过程,采用了事件代理,批量更新等方法,抹平了各个浏览器的事件兼容性问题。
# 跨平台兼容

VitrualDom为React带来了跨平台渲染的能力。以React Native为例子。React根据VitrualDom画出相应平台的ui层,只不过不同平台画的姿势不同而已。
# 虚拟 DOM 实现原理
如果你不想看繁杂的源码,或者现在没有足够时间,可以跳过这一章,直接 👇虚拟 DOM 原理总结 (opens new window)
在上面的图上我们继续进行扩展,按照图中的流程,我们依次来分析虚拟DOM的实现原理。
# JSX 和 createElement
我们在实现一个React组件时可以选择两种编码方式,第一种是使用JSX编写:
class Hello extends Component {
render() {
return <div>Hello ConardLi</div>;
}
}
第二种是直接使用React.createElement编写:
class Hello extends Component {
render() {
return React.createElement("div", null, `Hello ConardLi`);
}
}
实际上,上面两种写法是等价的,JSX只是为 React.createElement(component, props, ...children)方法提供的语法糖。也就是说所有的JSX代码最后都会转换成React.createElement(...),Babel帮助我们完成了这个转换的过程。
如下面的JSX
<div>
<img src="avatar.png" className="profile" />
<Hello />
</div>
将会被Babel转换为
React.createElement(
"div",
null,
React.createElement("img", {
src: "avatar.png",
className: "profile",
}),
React.createElement(Hello, null)
);
注意,babel在编译时会判断JSX中组件的首字母,当首字母为小写时,其被认定为原生DOM标签,createElement的第一个变量被编译为字符串;当首字母为大写时,其被认定为自定义组件,createElement的第一个变量被编译为对象;
另外,由于JSX提前要被Babel编译,所以JSX是不能在运行时动态选择类型的,比如下面的代码:
function Story(props) {
// Wrong! JSX type can't be an expression.
return <components[props.storyType] story={props.story} />;
}
需要变成下面的写法:
function Story(props) {
// Correct! JSX type can be a capitalized variable.
const SpecificStory = components[props.storyType];
return <SpecificStory story={props.story} />;
}
所以,使用JSX你需要安装Babel插件babel-plugin-transform-react-jsx
{
"plugins": [
["transform-react-jsx", {
"pragma": "React.createElement"
}]
]
}
# 创建虚拟 DOM
下面我们来看看虚拟DOM的真实模样,将下面的JSX代码在控制台打印出来:
<div className="title">
<span>Hello ConardLi</span>
<ul>
<li>苹果</li>
<li>橘子</li>
</ul>
</div>

这个结构和我们上面自己描绘的结构很像,那么React是如何将我们的代码转换成这个结构的呢,下面我们来看看createElement函数的具体实现(文中的源码经过精简)。
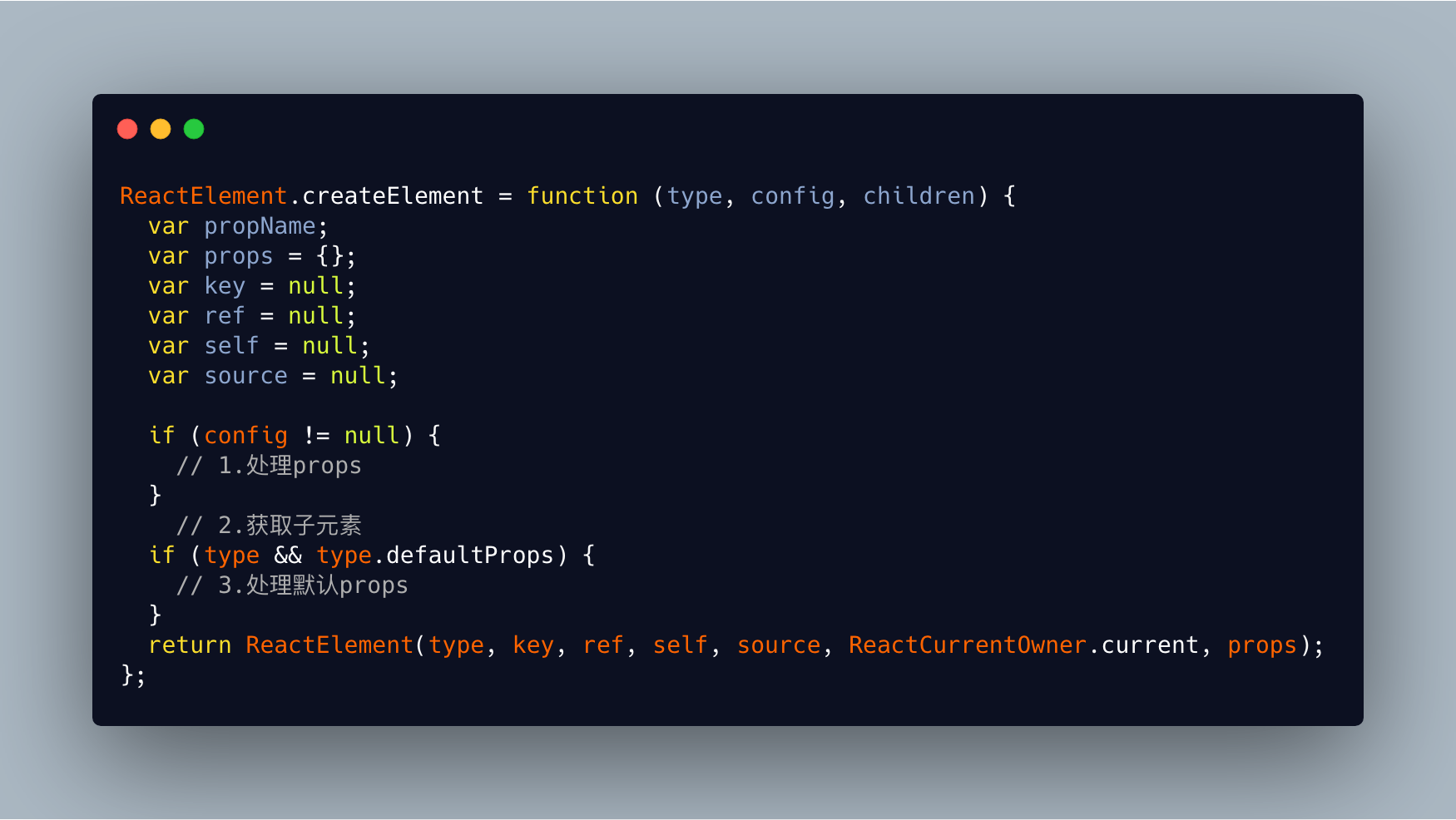
createElement函数内部做的操作很简单,将props和子元素进行处理后返回一个ReactElement对象,下面我们来逐一分析:
(1).处理 props:

- 1.将特殊属性
ref、key从config中取出并赋值 - 2.将特殊属性
self、source从config中取出并赋值 - 3.将除特殊属性的其他属性取出并赋值给
props
后面的文章会详细介绍这些特殊属性的作用。
(2).获取子元素
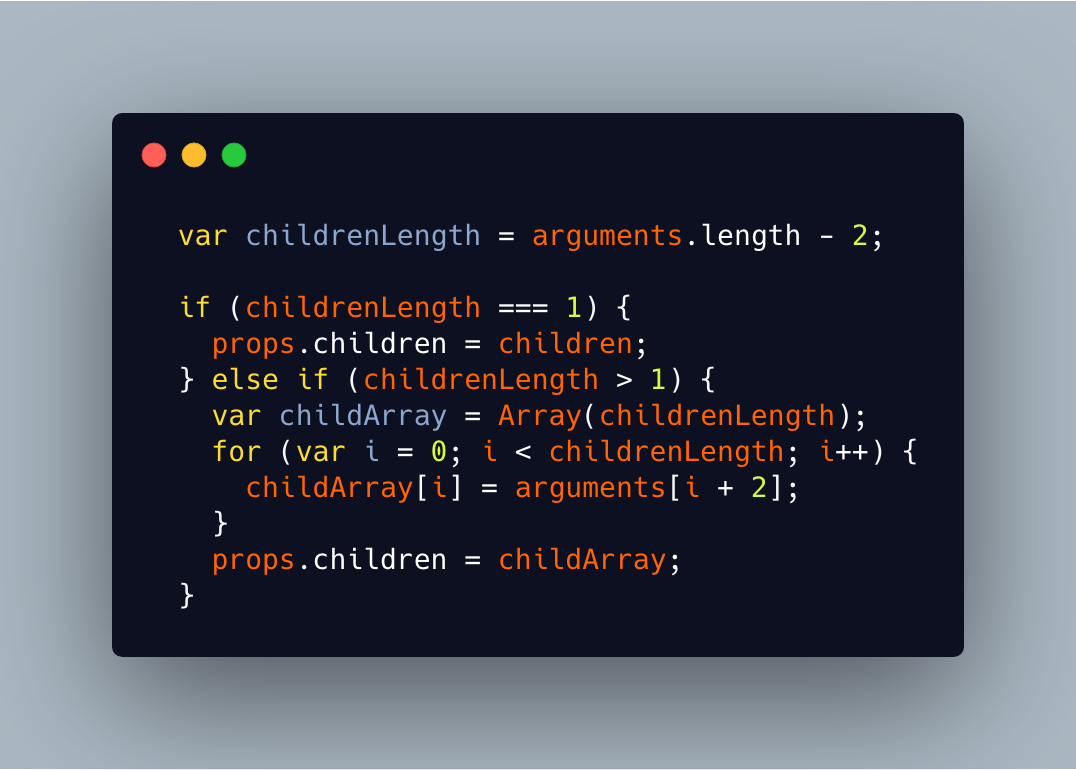
- 1.获取子元素的个数 —— 第二个参数后面的所有参数
- 2.若只有一个子元素,赋值给
props.children - 3.若有多个子元素,将子元素填充为一个数组赋值给
props.children
(3).处理默认 props
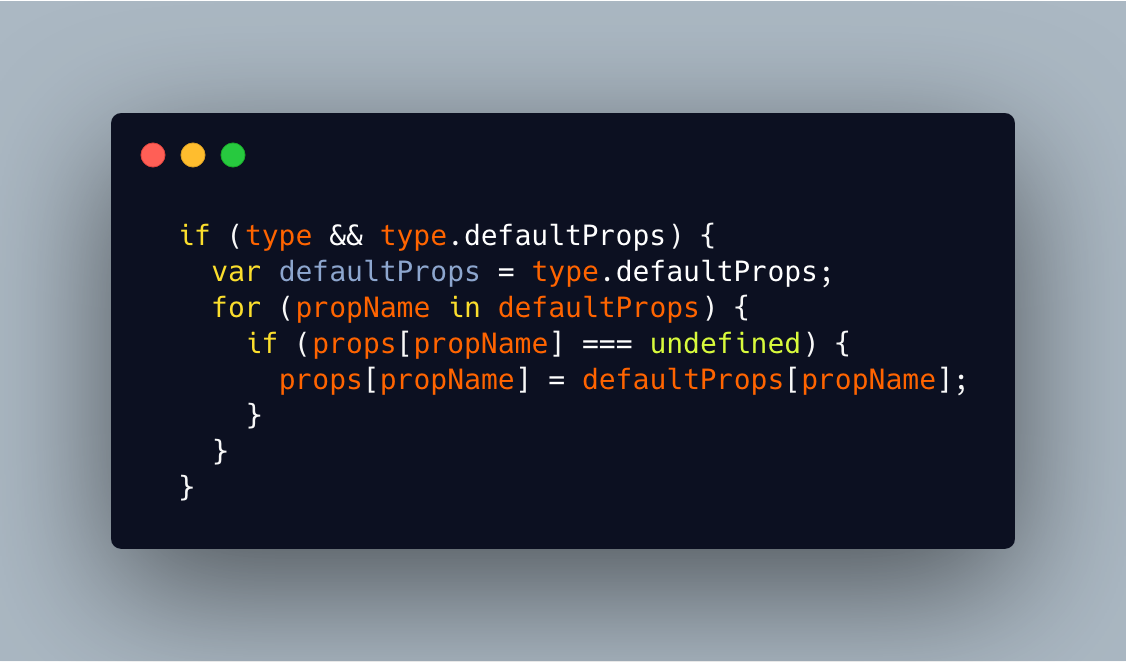
- 将组件的静态属性
defaultProps定义的默认props进行赋值
ReactElement
ReactElement将传入的几个属性进行组合,并返回。
type:元素的类型,可以是原生 html 类型(字符串),或者自定义组件(函数或class)key:组件的唯一标识,用于Diff算法,下面会详细介绍ref:用于访问原生dom节点props:传入组件的propsowner:当前正在构建的Component所属的Component
$$typeof:一个我们不常见到的属性,它被赋值为REACT_ELEMENT_TYPE:
var REACT_ELEMENT_TYPE =
(typeof Symbol === "function" && Symbol.for && Symbol.for("react.element")) ||
0xeac7;
可见,$$typeof是一个Symbol类型的变量,这个变量可以防止XSS。
如果你的服务器有一个漏洞,允许用户存储任意JSON对象, 而客户端代码需要一个字符串,这可能会成为一个问题:
// JSON
let expectedTextButGotJSON = {
type: "div",
props: {
dangerouslySetInnerHTML: {
__html: "/* put your exploit here */",
},
},
};
let message = { text: expectedTextButGotJSON };
<p>{message.text}</p>;
JSON中不能存储Symbol类型的变量。
ReactElement.isValidElement函数用来判断一个React组件是否是有效的,下面是它的具体实现。
ReactElement.isValidElement = function(object) {
return (
typeof object === "object" &&
object !== null &&
object.$$typeof === REACT_ELEMENT_TYPE
);
};
可见React渲染时会把没有$$typeof标识,以及规则校验不通过的组件过滤掉。
当你的环境不支持Symbol时,$$typeof被赋值为0xeac7,至于为什么,React开发者给出了答案:
0xeac7看起来有点像React。
self、source只有在非生产环境才会被加入对象中。
self指定当前位于哪个组件实例。_source指定调试代码来自的文件(fileName)和代码行数(lineNumber)。
# 虚拟 DOM 转换为真实 DOM
上面我们分析了代码转换成了虚拟DOM的过程,下面来看一下React如何将虚拟DOM转换成真实DOM。
本部分逻辑较复杂,我们先用流程图梳理一下整个过程,整个过程大概可分为四步:
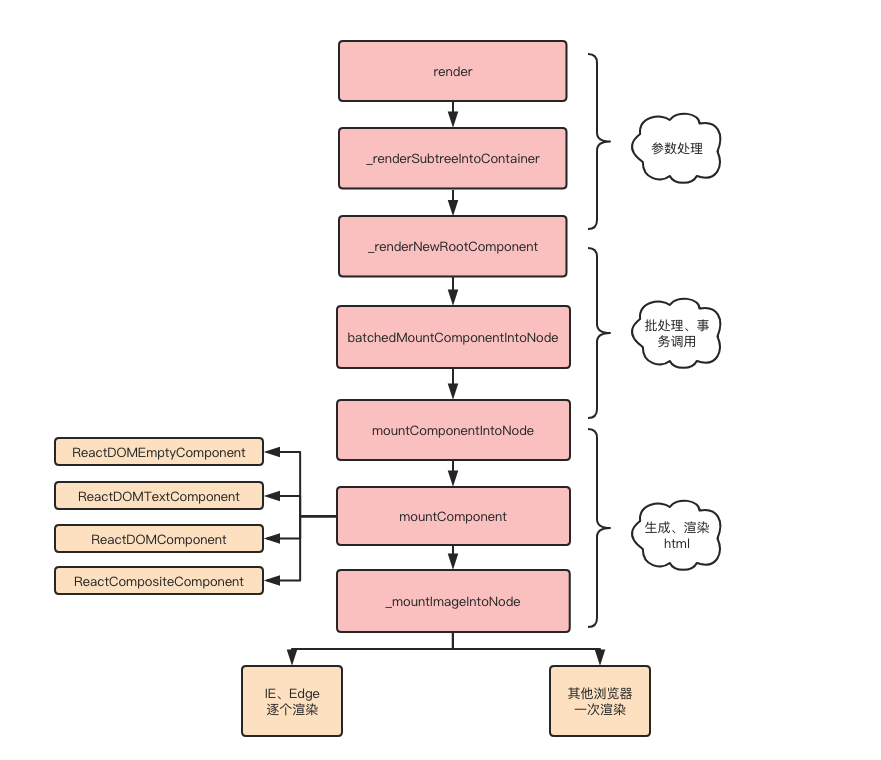
过程 1:初始参数处理
在编写好我们的React组件后,我们需要调用ReactDOM.render(element, container[, callback])将组件进行渲染。
render函数内部实际调用了_renderSubtreeIntoContainer,我们来看看它的具体实现:
render: function (nextElement, container, callback) {
return ReactMount._renderSubtreeIntoContainer(null, nextElement, container, callback);
},

- 1.将当前组件使用
TopLevelWrapper进行包裹
TopLevelWrapper只一个空壳,它为你需要挂载的组件提供了一个rootID属性,并在render函数中返回该组件。
TopLevelWrapper.prototype.render = function() {
return this.props.child;
};
ReactDOM.render函数的第一个参数可以是原生DOM也可以是React组件,包裹一层TopLevelWrapper可以在后面的渲染中将它们进行统一处理,而不用关心是否原生。
- 2.判断根结点下是否已经渲染过元素,如果已经渲染过,判断执行更新或者卸载操作
- 3.处理
shouldReuseMarkup变量,该变量表示是否需要重新标记元素 - 4.调用将上面处理好的参数传入
_renderNewRootComponent,渲染完成后调用callback。
在_renderNewRootComponent中调用instantiateReactComponent对我们传入的组件进行分类包装:
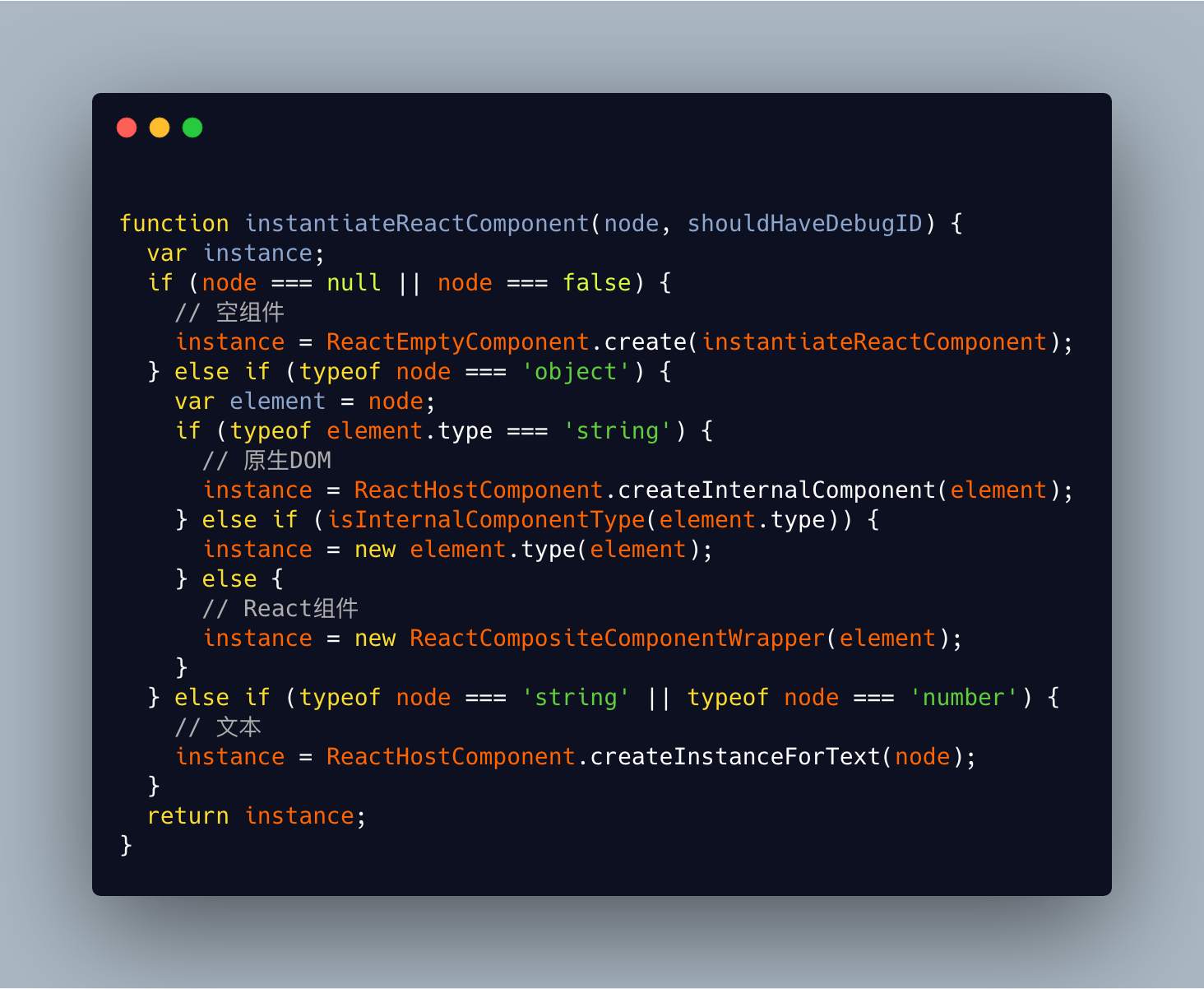
根据组件的类型,React根据原组件创建了下面四大类组件,对组件进行分类渲染:
ReactDOMEmptyComponent:空组件ReactDOMTextComponent:文本ReactDOMComponent:原生DOMReactCompositeComponent:自定义React组件
他们都具备以下三个方法:
construct:用来接收ReactElement进行初始化。mountComponent:用来生成ReactElement对应的真实DOM或DOMLazyTree。unmountComponent:卸载DOM节点,解绑事件。
具体是如何渲染我们在过程 3 中进行分析。
过程 2:批处理、事务调用
在_renderNewRootComponent中使用ReactUpdates.batchedUpdates调用batchedMountComponentIntoNode进行批处理。
ReactUpdates.batchedUpdates(
batchedMountComponentIntoNode,
componentInstance,
container,
shouldReuseMarkup,
context
);
在batchedMountComponentIntoNode中,使用transaction.perform调用mountComponentIntoNode让其基于事务机制进行调用。
transaction.perform(
mountComponentIntoNode,
null,
componentInstance,
container,
transaction,
shouldReuseMarkup,
context
);
关于批处理事务,在我前面的分析setState 执行机制 (opens new window)中有更多介绍。
过程 3:生成 html
在mountComponentIntoNode函数中调用ReactReconciler.mountComponent生成原生DOM节点。
mountComponent内部实际上是调用了过程 1 生成的四种对象的mountComponent方法。首先来看一下ReactDOMComponent:
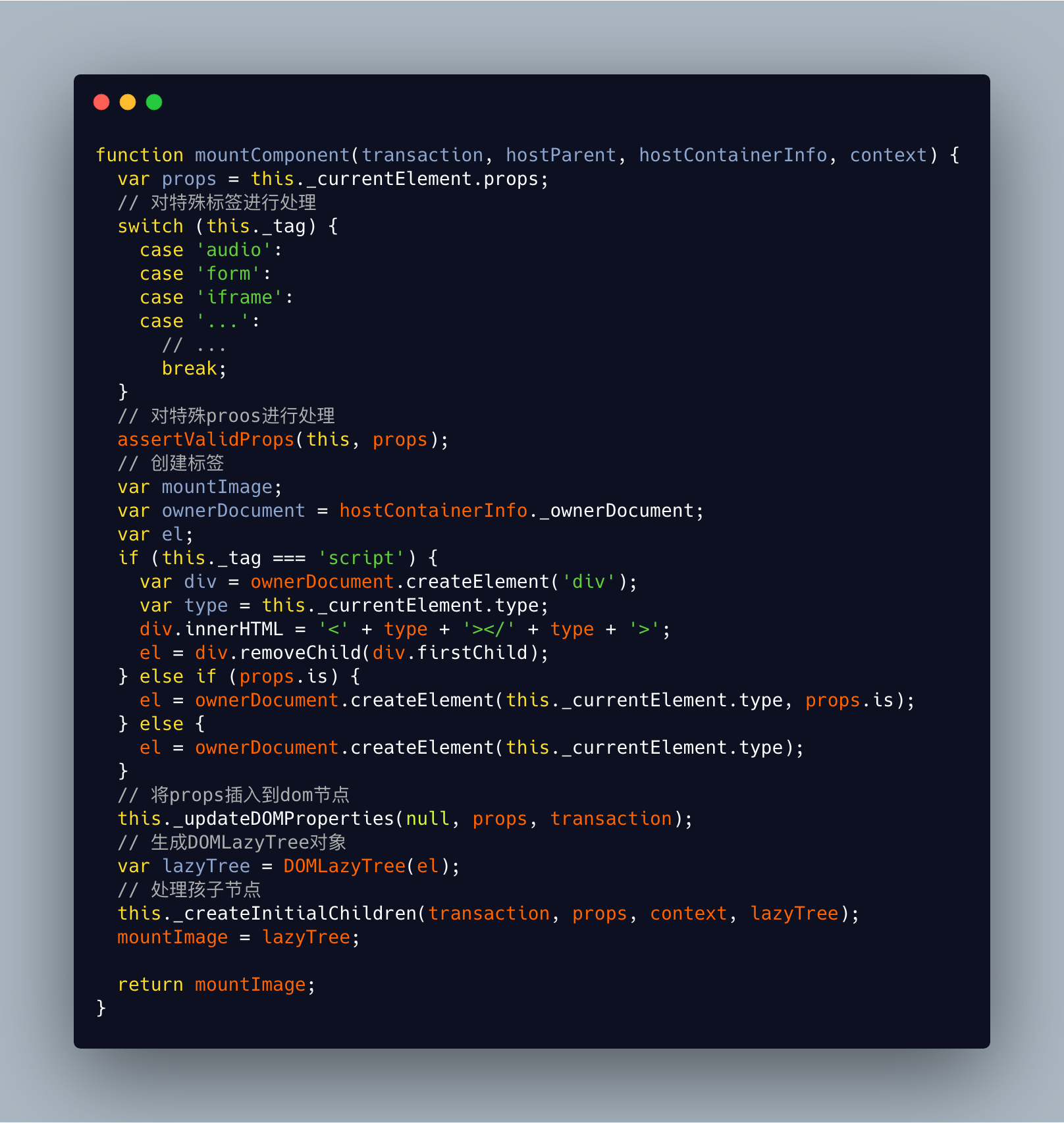
- 1.对特殊
DOM标签、props进行处理。 - 2.根据标签类型创建
DOM节点。 - 3.调用
_updateDOMProperties将props插入到DOM节点,_updateDOMProperties也可用于props Diff,第一个参数为上次渲染的props,第二个参数为当前props,若第一个参数为空,则为首次创建。 - 4.生成一个
DOMLazyTree对象并调用_createInitialChildren将孩子节点渲染到上面。
那么为什么不直接生成一个DOM节点而是要创建一个DOMLazyTree呢?我们先来看看_createInitialChildren做了什么:
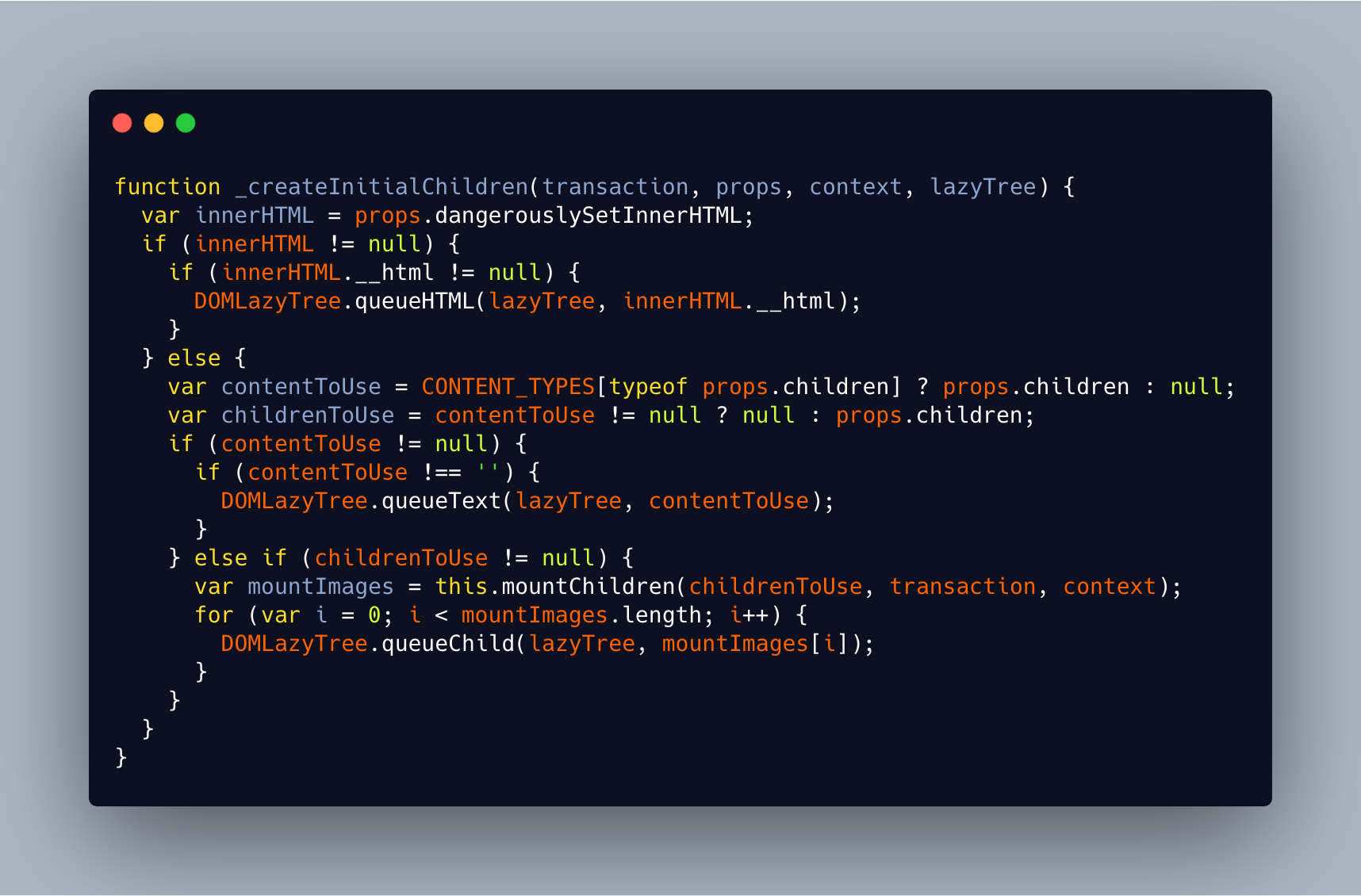
判断当前节点的dangerouslySetInnerHTML属性、孩子节点是否为文本和其他节点分别调用DOMLazyTree的queueHTML、queueText、queueChild。
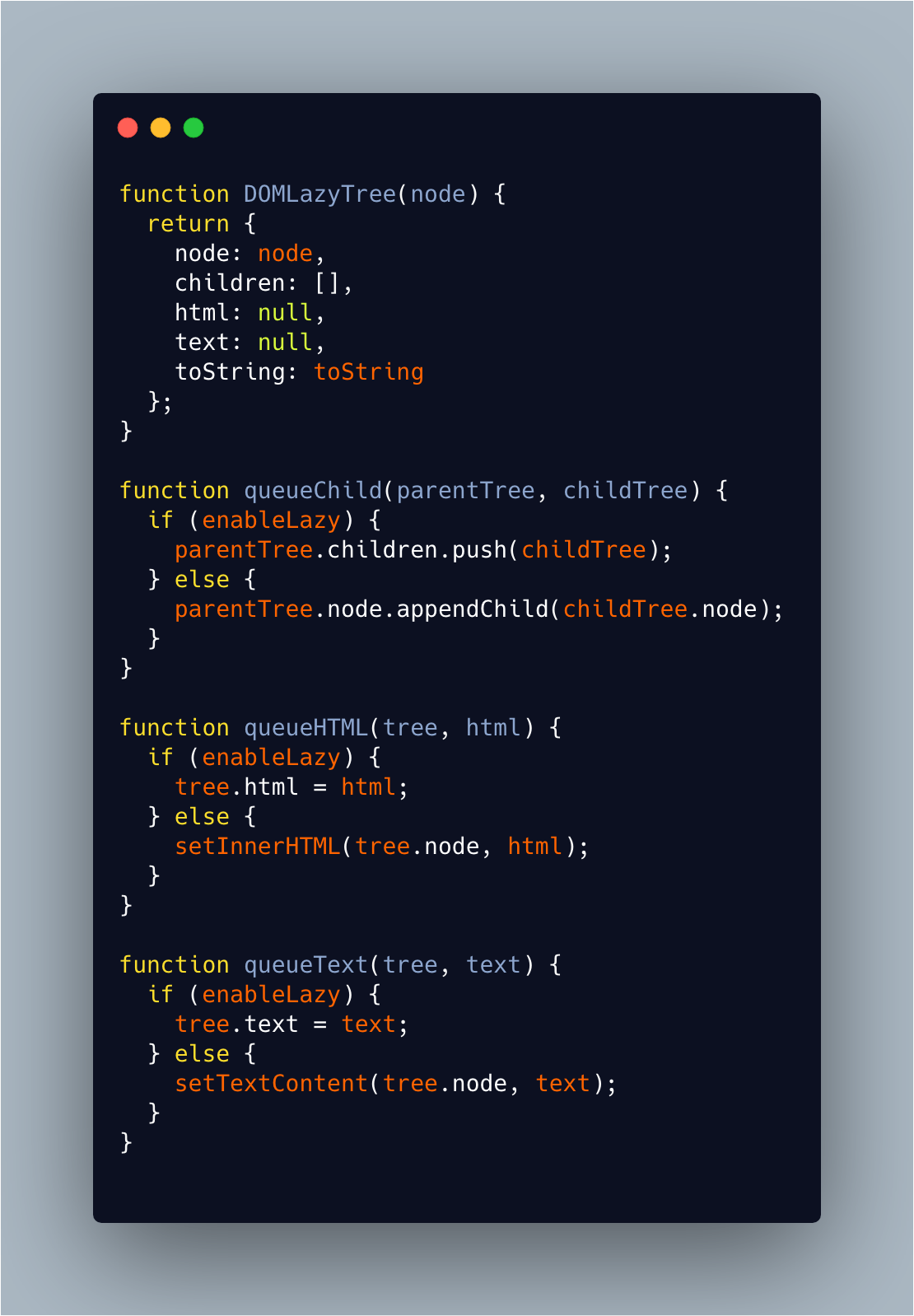
可以发现:DOMLazyTree实际上是一个包裹对象,node属性中存储了真实的DOM节点,children、html、text分别存储孩子、html 节点和文本节点。
它提供了几个方法用于插入孩子、html以及文本节点,这些插入都是有条件限制的,当enableLazy属性为true时,这些孩子、html以及文本节点会被插入到DOMLazyTree对象中,当其为false时会插入到真实DOM节点中。
var enableLazy =
(typeof document !== "undefined" &&
typeof document.documentMode === "number") ||
(typeof navigator !== "undefined" &&
typeof navigator.userAgent === "string" &&
/\bEdge\/\d/.test(navigator.userAgent));
可见:enableLazy是一个变量,当前浏览器是IE或Edge时为true。
在IE(8-11)和Edge浏览器中,一个一个插入无子孙的节点,效率要远高于插入一整个序列化完整的节点树。
所以lazyTree主要解决的是在IE(8-11)和Edge浏览器中插入节点的效率问题,在后面的过程 4 我们会分析到:若当前是IE或Edge,则需要递归插入DOMLazyTree中缓存的子节点,其他浏览器只需要插入一次当前节点,因为他们的孩子已经被渲染好了,而不用担心效率问题。
下面来看一下ReactCompositeComponent,由于代码非常多这里就不再贴这个模块的代码,其内部主要做了以下几步:
- 处理
props、contex等变量,调用构造函数创建组件实例 - 判断是否为无状态组件,处理
state - 调用
performInitialMount生命周期,处理子节点,获取markup。 - 调用
componentDidMount生命周期
在performInitialMount函数中,首先调用了componentWillMount生命周期,由于自定义的React组件并不是一个真实的 DOM,所以在函数中又调用了孩子节点的mountComponent。这也是一个递归的过程,当所有孩子节点渲染完成后,返回markup并调用componentDidMount。
过程 4:渲染 html
在mountComponentIntoNode函数中调用将上一步生成的markup插入container容器。
在首次渲染时,_mountImageIntoNode会清空container的子节点后调用DOMLazyTree.insertTreeBefore:
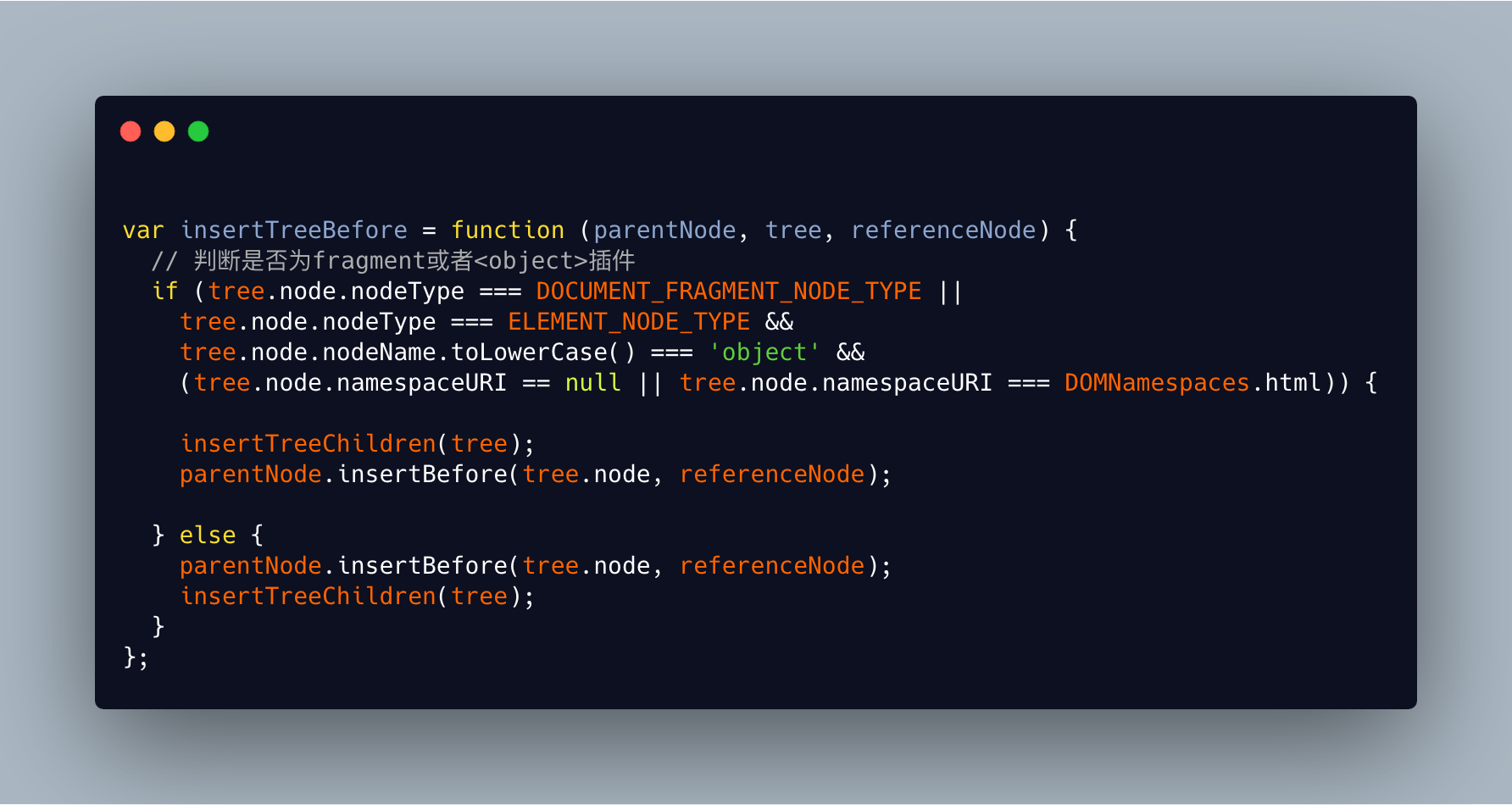
判断是否为fragment节点或者<object>插件:
- 如果是以上两种,首先调用
insertTreeChildren将此节点的孩子节点渲染到当前节点上,再将渲染完的节点插入到html - 如果是其他节点,先将节点插入到插入到
html,再调用insertTreeChildren将孩子节点插入到html。 - 若当前不是
IE或Edge,则不需要再递归插入子节点,只需要插入一次当前节点。
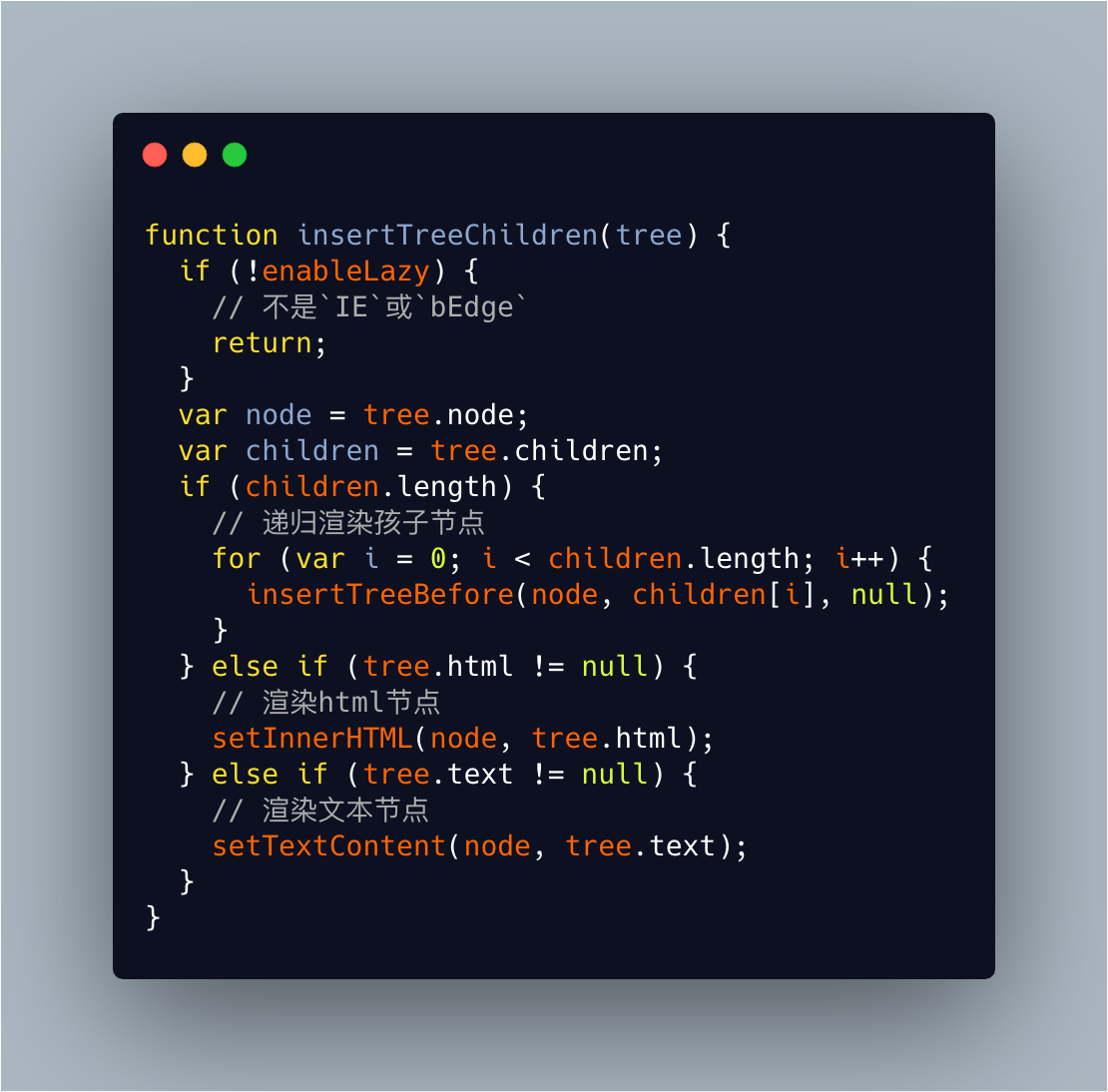
- 判断不是
IE或bEdge时return - 若
children不为空,递归insertTreeBefore进行插入 - 渲染 html 节点
- 渲染文本节点
# 原生 DOM 事件代理
有关虚拟DOM的事件机制,我曾专门写过一篇文章,有兴趣可以 👇【React 深入】React 事件机制 (opens new window)
# 虚拟 DOM 原理、特性总结
# React 组件的渲染流程
- 使用
React.createElement或JSX编写React组件,实际上所有的JSX代码最后都会转换成React.createElement(...),Babel帮助我们完成了这个转换的过程。 createElement函数对key和ref等特殊的props进行处理,并获取defaultProps对默认props进行赋值,并且对传入的孩子节点进行处理,最终构造成一个ReactElement对象(所谓的虚拟DOM)。ReactDOM.render将生成好的虚拟DOM渲染到指定容器上,其中采用了批处理、事务等机制并且对特定浏览器进行了性能优化,最终转换为真实DOM。
# 虚拟 DOM 的组成
即ReactElementelement 对象,我们的组件最终会被渲染成下面的结构:
type:元素的类型,可以是原生 html 类型(字符串),或者自定义组件(函数或class)key:组件的唯一标识,用于Diff算法,下面会详细介绍ref:用于访问原生dom节点props:传入组件的props,chidren是props中的一个属性,它存储了当前组件的孩子节点,可以是数组(多个孩子节点)或对象(只有一个孩子节点)owner:当前正在构建的Component所属的Componentself:(非生产环境)指定当前位于哪个组件实例_source:(非生产环境)指定调试代码来自的文件(fileName)和代码行数(lineNumber)
# 防止 XSS
ReactElement对象还有一个$$typeof属性,它是一个Symbol类型的变量Symbol.for('react.element'),当环境不支持Symbol时,$$typeof被赋值为0xeac7。
这个变量可以防止XSS。如果你的服务器有一个漏洞,允许用户存储任意JSON对象, 而客户端代码需要一个字符串,这可能为你的应用程序带来风险。JSON中不能存储Symbol类型的变量,而React渲染时会把没有$$typeof标识的组件过滤掉。
# 批处理和事务
React在渲染虚拟DOM时应用了批处理以及事务机制,以提高渲染性能。
关于批处理以及事务机制,在我之前的文章【React 深入】setState 的执行机制 (opens new window)中有详细介绍。
# 针对性的性能优化
在IE(8-11)和Edge浏览器中,一个一个插入无子孙的节点,效率要远高于插入一整个序列化完整的节点树。
React通过lazyTree,在IE(8-11)和Edge中进行单个节点依次渲染节点,而在其他浏览器中则首先将整个大的DOM结构构建好,然后再整体插入容器。
并且,在单独渲染节点时,React还考虑了fragment等特殊节点,这些节点则不会一个一个插入渲染。
# 虚拟 DOM 事件机制
React自己实现了一套事件机制,其将所有绑定在虚拟DOM上的事件映射到真正的DOM事件,并将所有的事件都代理到document上,自己模拟了事件冒泡和捕获的过程,并且进行统一的事件分发。
React自己构造了合成事件对象SyntheticEvent,这是一个跨浏览器原生事件包装器。 它具有与浏览器原生事件相同的接口,包括stopPropagation()和preventDefault()等等,在所有浏览器中他们工作方式都相同。这抹平了各个浏览器的事件兼容性问题。
上面只分析虚拟DOM首次渲染的原理和过程,当然这并不包括虚拟 DOM进行 Diff的过程,下一篇文章我们再来详细探讨。
关于开篇提的几个问题,我们在下篇文章中进行统一回答。